
AI-Powered Search Revolution
OpenAI has unveiled SearchGPT, a prototype AI-powered search engine that aims to challenge Google's dominance in online search. SearchGPT combines OpenAI's AI models, including ChatGPT, with real-time web information to provide fast, conversational answers along with clear links to relevant sources 1 3. The system is designed to enhance the search experience by highlighting high-quality content in a user-friendly interface 2. Currently available to a limited group of 10,000 test users and select publishers, OpenAI plans to integrate the best features of SearchGPT directly into ChatGPT in the future 1 2. This move positions OpenAI as a direct competitor to major search platforms like Google and Microsoft's Bing, potentially disrupting the online search market 3.
Yandex LLM Compression Techniques
Yandex Research, in collaboration with IST Austria, NeuralMagic, and KAUST, has developed and open-sourced two innovative large language model (LLM) compression methods: Additive Quantization for Language Models (AQLM) and PV-Tuning. 1 2 These techniques aim to address the growing computational demands of LLMs by enabling efficient compression without significant loss in performance. AQLM allows for compressing LLMs to as low as 2 bits per parameter, potentially reducing model size by up to 16 times compared to standard 32-bit formats. 2 This advancement is particularly significant as it could make running large AI models more accessible and cost-effective for developers and researchers, potentially accelerating progress in the field of artificial intelligence.

Enterprise Data Intelligence
NVIDIA has introduced NeMo Retriever, a new generative AI microservice designed to enhance the accuracy and capabilities of enterprise AI applications. Part of the NVIDIA NeMo platform, NeMo Retriever enables organizations to connect custom large language models (LLMs) to their proprietary data sources, facilitating highly accurate responses through retrieval-augmented generation (RAG) 2 4. This microservice offers GPU-accelerated tools for tasks such as document ingestion, semantic search, and interaction with existing databases, built on NVIDIA's software suite including CUDA, TensorRT, and Triton Inference Server 4. Major companies like Adobe, Cloudera, and NetApp are collaborating with NVIDIA to leverage NeMo Retriever, aiming to transform vast amounts of enterprise data into valuable business insights 4. The microservice is available through the NVIDIA API catalog and is part of the NVIDIA AI Enterprise software platform, supporting deployment across various cloud and data center environments 5.
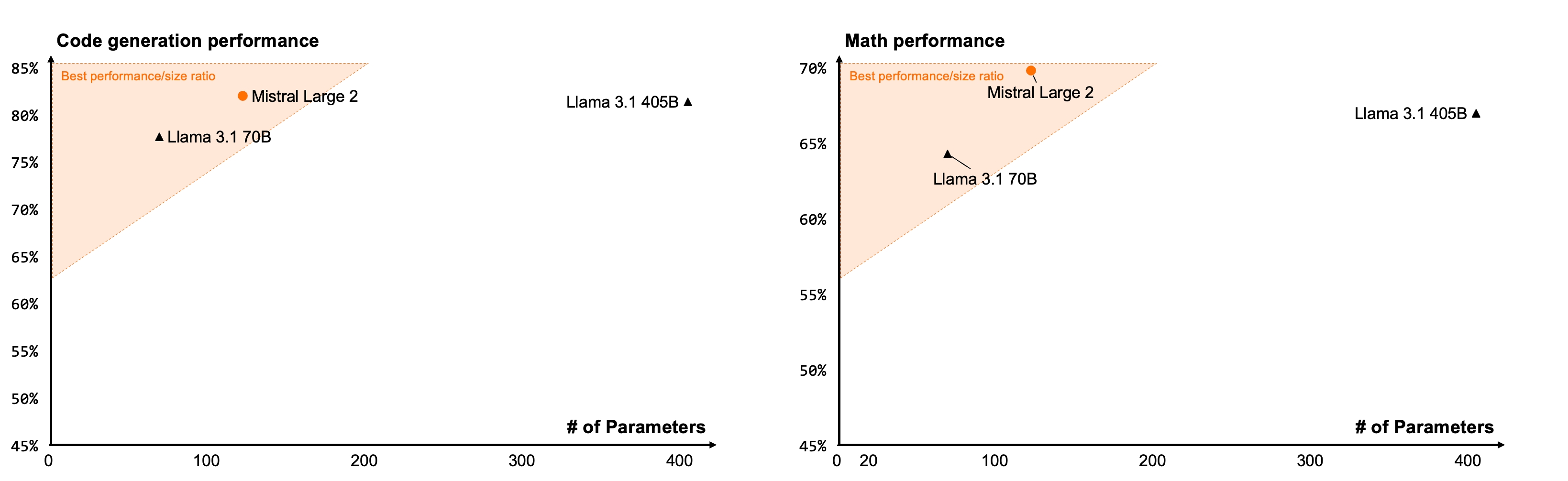
Powerful Multilingual AI Model
Mistral AI has unveiled Mistral Large 2 (ML2), a 123-billion-parameter large language model that claims to rival top models from OpenAI, Anthropic, and Meta in performance while using significantly fewer resources 5. ML2 boasts a 128,000 token context window, support for dozens of languages, and over 80 coding languages 3. According to Mistral's benchmarks, ML2 achieves an 84% score on the Massive Multitask Language Understanding (MMLU) test, approaching the performance of GPT-4 and Claude 3.5 Sonnet 5. Notably, ML2's smaller size compared to competitors allows for higher throughput and easier deployment on single servers with multiple GPUs, making it an attractive option for commercial applications 5. The model is available through Mistral's platform "la Plateforme" and Microsoft Azure, with a research license for non-commercial use 3 2.

Open AI Powerhouse
Meta has unveiled Llama 3.1, a series of open-source AI models that represent a significant advancement in the field of artificial intelligence. The flagship model, Llama 3.1 405B, boasts 405 billion parameters and is touted as the world's largest and most capable openly available foundation model 1 3. This model, along with updated 8B and 70B versions, offers improved capabilities in general knowledge, reasoning, tool use, and multilingual translation 5. Trained on over 15 trillion tokens using 16,000 Nvidia H100 GPUs, Llama 3.1 aims to compete with leading closed-source models like GPT-4 and Claude 3.5 Sonnet [undefined][3](https://www.wired.com/story/meta-ai-llama-3/). Meta's open-source approach allows developers to customize and enhance these models for various applications, potentially accelerating innovation in AI development 4. The release of Llama 3.1 marks a shift towards open-source AI becoming an industry standard, with Meta partnering with cloud providers to make the models widely accessible for enterprise use 4 5.

AI Model Collaboration
Mistral AI and NVIDIA have unveiled Mistral NeMo 12B, a state-of-the-art language model designed for enterprise applications such as chatbots, multilingual tasks, coding, and summarization 1 4. This 12-billion-parameter model boasts a 128K context length, allowing it to process extensive and complex information more coherently and accurately 2 4. Trained on NVIDIA's DGX Cloud AI platform using 3,072 H100 80GB Tensor Core GPUs, Mistral NeMo 12B leverages Mistral AI's expertise in training data and NVIDIA's optimized hardware and software ecosystem 1 4. The model is released under the Apache 2.0 license, supports FP8 data format for efficient inference, and is packaged as an NVIDIA NIM inference microservice for easy deployment 2 4. Designed to fit on memory-efficient accelerators like NVIDIA L40S, GeForce RTX 4090, or RTX 4500 GPUs, Mistral NeMo offers high efficiency, low compute costs, and enhanced security features 3 4.

Cost-Efficient Multimodal Model
OpenAI has introduced GPT-4o mini, a cost-efficient small model designed to make AI more accessible and affordable. This multimodal model supports text and vision inputs, with a 128K token context window and knowledge up to October 2023 2. GPT-4o mini outperforms GPT-3.5 Turbo on various benchmarks while being more than 60% cheaper, priced at 15 cents per million input tokens and 60 cents per million output tokens 2. The model is now available in the Assistants API, Chat Completions API, and Batch API, with fine-tuning capabilities planned for release 2 4. While OpenAI has not disclosed the exact size of GPT-4o mini, it is reportedly in the same tier as other small AI models like Llama 3 8b, Claude Haiku, and Gemini 1.5 Flash 3.