Grok 2 Release Imminent
Elon Musk's xAI is set to release Grok 2, an upgraded version of its AI chatbot, in August 2024. This new iteration promises significant improvements, particularly in purging large language models (LLMs) from internet training data, addressing concerns about data quality and relevance. Grok 2 is expected to surpass current AI models on various metrics and will feature real-time web search integration and image generation capabilities. Following Grok 2, Musk has announced plans for Grok 3, slated for release by the end of 2024. Grok 3 will undergo training on an impressive 100,000 Nvidia H100 GPUs, potentially setting new benchmarks in the field of artificial intelligence.123.
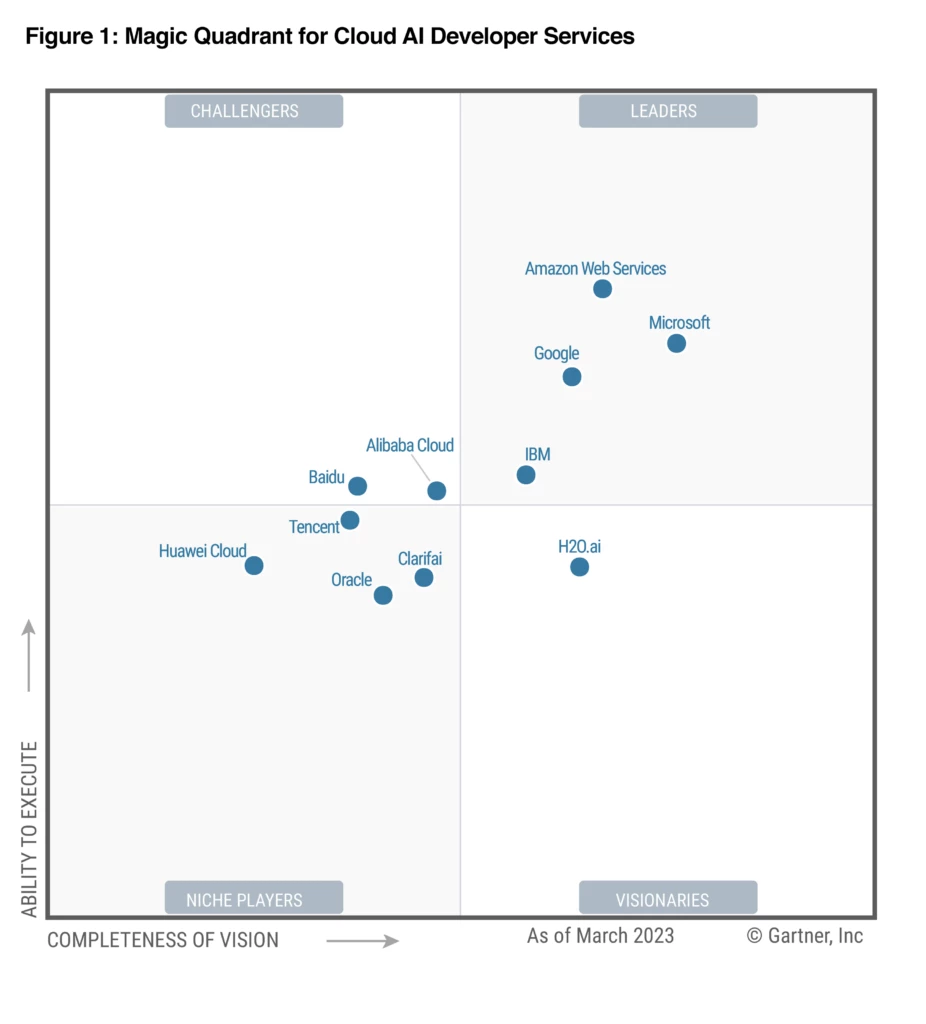
Cloud-Driven AI Acceleration
Gartner predicts that the ongoing price war in China's Large Language Model (LLM) market will accelerate the shift of AI development towards cloud platforms. This prediction comes amid a fierce competition among Chinese tech giants, including Alibaba, Tencent, and Baidu, who have significantly slashed prices for their LLM offerings. The price cuts, reaching up to 97% in some cases, are expected to drive wider adoption of AI technologies across various industries. As LLMs become more affordable and accessible, they are likely to be viewed as essential infrastructure, similar to utilities like water and electricity. This trend is anticipated to not only boost the development of China's LLM sector but also accelerate the launch of more advanced AI language models, potentially narrowing the gap with US counterparts.123

Alibaba's Math-Focused AI
Alibaba Cloud has unveiled Qwen2-Math, a series of mathematics-focused large language models (LLMs) that reportedly outperform leading AI models in mathematical tasks. The most advanced model, Qwen2-Math-72B-Instruct, has demonstrated superior performance on various math benchmarks compared to models like GPT-4, Claude 3.5 Sonnet, and Google's Gemini 1.5 Pro. These models, based on the general Qwen2 language models, underwent additional pre-training on a specialized math corpus, enabling them to excel in solving complex mathematical problems. While currently supporting primarily English, Alibaba plans to release bilingual and multilingual versions in the future, potentially expanding the models' applicability across different languages and regions.123

AI Text Watermarking Tool
OpenAI has developed a highly effective text watermarking tool capable of detecting AI-generated content with 99.9% accuracy, but has not yet released it publicly due to ongoing internal debates. The tool works by adding an imperceptible pattern to ChatGPT's output, allowing OpenAI to identify content created by its AI model. However, concerns have been raised about potential biases against non-native English writers and the ease with which the watermarking could be circumvented through methods like translation or rephrasing. Additionally, OpenAI is weighing customer feedback, with 69% of ChatGPT users expressing concerns about false accusations of AI cheating and 30% indicating they might switch to rival LLMs if such a tool were deployed. Despite these challenges, OpenAI recognizes the societal risks posed by AI-generated content and is exploring alternative approaches to address transparency and responsible AI use.123

HuggingFace Acquires XetHub
Hugging Face, a leading platform for open-source machine learning projects, has acquired XetHub, a Seattle-based data storage and collaboration startup founded by former Apple engineers. This acquisition, the largest in Hugging Face's history, aims to enhance the company's ability to host and manage large AI models and datasets. XetHub's technology enables Git-like version control for repositories up to terabytes in size, offering advanced features like content-defined chunking and deduplication. By integrating XetHub's capabilities, Hugging Face plans to upgrade its storage backend, potentially allowing for individual files larger than 1TB and total repository sizes exceeding 100TB. This move is expected to significantly boost Hugging Face's infrastructure, supporting the growing demand for larger AI models and datasets in the rapidly evolving field of artificial intelligence.1234

GPT-4o Price Reduction
OpenAI has significantly reduced the pricing for its advanced GPT-4o model, making it more accessible to developers and businesses. The new gpt-4o-2024-08-06 model is now available at $2.50 per 1 million input tokens and $10.00 per 1 million output tokens, representing a 50% reduction for input tokens and a 33% reduction for output tokens compared to the previous version. This price cut positions GPT-4o competitively against Google's Gemini 1.5 Pro model, which costs $3.50 per 1 million input tokens and $10.50 per 1 million output tokens. Alongside the price reduction, OpenAI has introduced Structured Outputs in the API, ensuring model-generated outputs conform to specific JSON schemas provided by developers, enhancing the model's utility for various applications.1

Gemini Price War Intensifies
Google has significantly reduced the pricing for its Gemini 1.5 Flash model, cutting costs by approximately 80% effective August 12, 2024. The new pricing structure offers input tokens at $0.075 per million and output tokens at $0.30 per million for prompts up to 128,000 tokens, making it nearly 50% cheaper than OpenAI's competing GPT-4o mini model. This aggressive price reduction is part of an ongoing AI pricing war, with Google also expanding language support to over 100 languages and introducing enhanced PDF understanding capabilities. The move is expected to intensify competition in the AI market, potentially challenging smaller AI startups and forcing other major players to reconsider their pricing strategies. Despite the lower cost, Gemini 1.5 Flash still lags behind GPT-4o mini in most AI benchmarks, except for MathVista.123