Global AI Operations Dashboard: Complete Model Analytics Platform
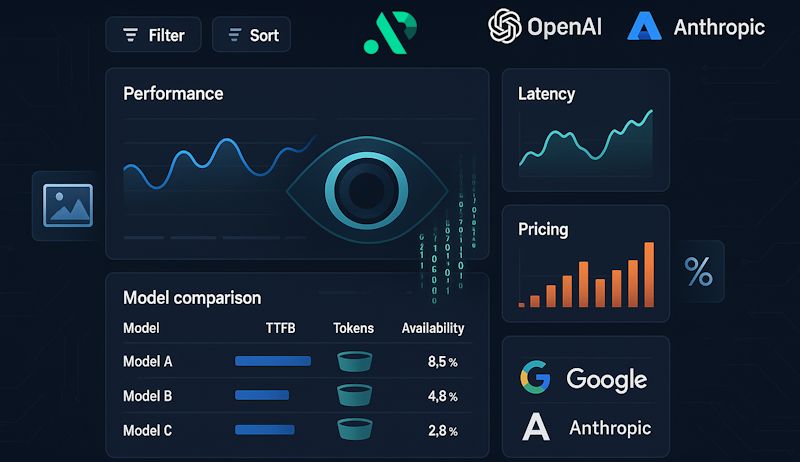
Transform your AI model selection process with our comprehensive Global AI Operations Dashboard. Access real-time performance metrics, pricing analytics, and advanced filtering capabilities to find the perfect AI model for your needs. Whether you're seeking the top AI API, comparing OpenAI competitors, or need a single AI solution across multiple providers, our API router dashboard provides unparalleled insights into the best AI APIs available.
Dashboard Overview
The APIpie Dashboard serves as your central command center for AI model analytics, providing comprehensive insights into hundreds of models across multiple providers. Our platform acts is a one API solution, giving you access to the best AI models from leading providers while offering detailed performance and cost analytics. Browse models easily with our intuitive interface to list models and discover available models across all providers.
Why APIpie is the top router for AI APIs
- Real-world pricing analytics - Not advertised rates, but where available actual router costs calculated from our proprietary algorithms
- Comprehensive latency tracking across multiple token bucket sizes (2K, 4K, 8K, 16K, 32K tokens)
- Time to First Chunk (TTFC) metrics for optimal streaming APIs performance
- Smart model grouping for easy comparison across providers in our model rankings
- Advanced filtering and sorting capabilities
- 30-day availability tracking with visual performance graphs for better uptime
- Multi-provider coverage including OpenAI, Anthropic, Google, Meta, and open source alternatives
Visit our live Dashboard to explore all available AI models with real-time performance metrics and pricing analytics.
Performance Metrics & Analytics
Our dashboard provides the most comprehensive AI model analytics platform available, tracking performance across multiple dimensions to help you find the top AI APIs for your use case. Discover your best LLM ranking and model ratings to help you identify your top models weekly through our dashboard.
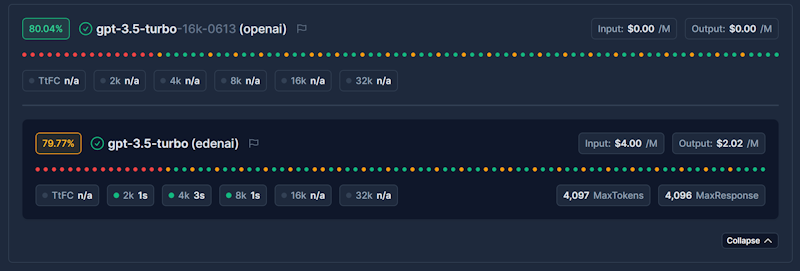
Latency Tracking Across Token Buckets
We measure and display latency performance across five different prompt/response size categories:
- 2K tokens - Short conversations and quick queries
- 4K tokens - Medium-length interactions and code generation
- 8K tokens - Complex reasoning and detailed analysis
- 16K tokens - Long-form content and document processing
- 32K tokens - Extended context and comprehensive analysis
Time to First Chunk (TTFC) Metrics
Critical for streaming router applications and real-time user experiences:
- Streaming responsiveness - How quickly users see the first response from our streaming APIs
- Provider comparison - TTFC performance across different providers
- Model optimization - Identify the fastest models for interactive applications
- User experience optimization - Choose models that provide the best perceived performance
Real-World Pricing Analytics
Unlike other platforms that show advertised rates, where available our pricing reflects actual costs:
- Proprietary cost algorithm calculating real service costs per model/provider
- Per-million-token pricing for transparent cost comparison
- Input and output pricing separately tracked
Advanced Filtering & Sorting
Dashboard V2 introduces powerful filtering and sorting capabilities, making it the ultimate ML & AI API selection tool for developers and enterprises. Browse models efficiently with our filtering system.
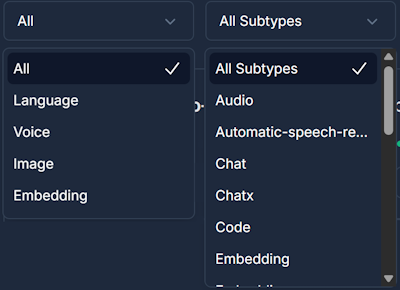
Filter by Model Types
- Language Models (LLMs) - Text generation, reasoning, and conversation
- Voice Models - Text-to-speech and audio processing
- Embedding Models - Vector representations for search and similarity
- Image Generation - Creative and artistic image creation
Filter by Subtypes
- Multimodal - Multimodal image analysis and Text OCR processing capabilities
- Chat - Conversational AI optimized for dialogue
- Code - Programming and software development focused
- Reasoning - Advanced logical thinking and problem-solving
- Tools - Function calling and external integration support
- & More - See the live dashboard for further model subtypes
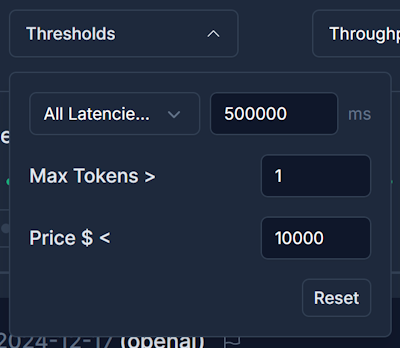
Performance-Based Filtering
- Latency thresholds - Exclude models above specific latency limits
- TTFC filtering - Show only models meeting streaming APIs requirements
- Context window - Filter by maximum token capacity
Pricing Filters
- Maximum cost per million tokens - Stay within budget constraints
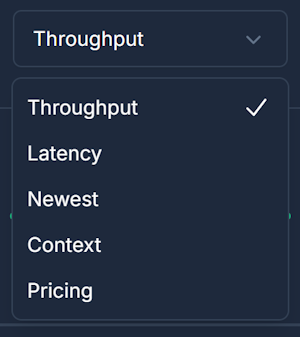
Sorting Capabilities
Organize models based on your priorities with our model ranking system:
Performance Sorting
- Throughput (ascending/descending) - Requests per minute capacity
- Latency (ascending/descending) - Average response time
- TTFC (ascending/descending) - Streaming router responsiveness
Model Characteristics
- Newest - Recently released models first
- Context size - Maximum token capacity
- Model size - Parameter count and model complexity
Cost Analysis
- Input pricing - Cost per million input tokens
- Output pricing - Cost per million output tokens
- Image cost - Standard Quality and size pricing
AI Router API & Model Discovery
Our base API and router API provide programmatic access to browse models, list models, and access available models across all providers. The AI fetch functionality enables seamless integration with your applications while our streaming APIs ensure optimal performance.
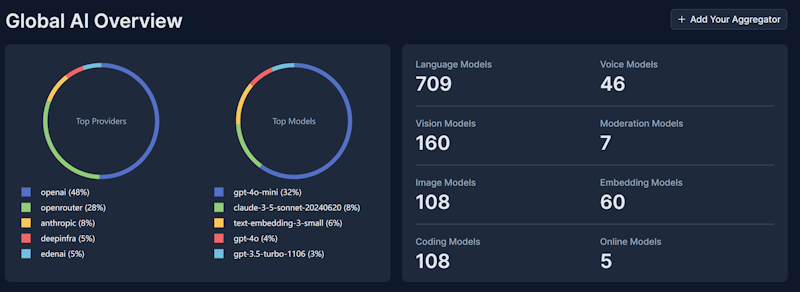
Model Categories & Statistics
Our dashboard provides comprehensive coverage of the AI ecosystem with detailed AI stats:
Language Models
- Hundreds of models across all major providers
- Text generation, reasoning, and conversation
- Specialized coding models and technical models
- Multilingual and domain-specific variants
Vision Models
- Multimodal models with image understanding
- OCR and document analysis capabilities
- Chart and diagram interpretation
- Visual question answering and description
Voice Models
- Text-to-speech models
- Multiple languages and voice styles
- Real-time and batch processing options
- High-quality audio generation
Specialized Models
- Image generation models for creative applications
- Coding models for software development with coder optimization
- Embedding models for vector operations
Provider Coverage
Access the best AI APIs from leading providers through our top ranked router platform:
Major Private Providers
- OpenAI - GPT-4, GPT-3.5, and specialized models
- Google Gemini - Advanced multimodal models and AI capabilities
- Anthropic - Claude family and safety-focused models
- Perplexity - Search-enhanced AI and reasoning models
- Amazon - Nova models and cloud AI services
- & MORE - Additional enterprise and specialized providers
Open Source Alternatives
- Meta Llama models - Open source language models
- Google Gemma - Lightweight and efficient models
- Microsoft Phi - Small but capable models
- Mistral models - European AI excellence
- Community models & More - Cutting-edge research implementations
Real-Time Model Monitoring
Stay informed with live performance tracking and better uptime monitoring:
Availability Monitoring
- 30-day availability statistics for each model with better uptime tracking
- Real-time status indicators showing current availability
- Historical uptime data for reliability assessment
- Provider reliability comparison across different services
Performance Tracking
- Live latency updates based on actual API calls
- TTFC monitoring for streaming APIs performance
- Throughput capacity tracking and limits
- Error rate monitoring and quality metrics
- AI stats for comprehensive performance analysis
Cost Tracking
- Real-time pricing updates reflecting actual
- Historical cost trends and pricing changes
- Provider cost comparison for identical models
- Budget impact analysis for cost optimization
Using the Dashboard Effectively��
Finding the Best AI Model
- Define your requirements - Determine needed capabilities (text, vision, voice, etc.)
- Set performance criteria - Establish latency and quality requirements
- Apply filters - Narrow down options based on your needs
- Browse models - Use our interface to list models and explore available models
- Compare grouped models - Expand clusters to see provider comparisons
- Analyze metrics - Review latency, cost, and availability data with AI stats
- Test desired models - Use our router API to validate performance
Optimizing for Cost-Performance
- Filter by budget constraints to stay within spending limits
- Compare provider pricing for identical model capabilities
- Consider token bucket performance for your specific use case
Ensuring Reliability
- Check 30-day availability statistics for each model with better uptime metrics
- Review provider reliability across different services
- Monitor real-time status before critical deployments
- Track API limitations to avoid service interruptions
API Access to Dashboard Data
Access dashboard insights programmatically through our base API and router API:
- AI fetch capabilities for real-time model data
- Streaming APIs for live performance metrics
- AI stats and analytics data access
Cost Management
- Monitor pricing trends for budget planning
- Compare provider costs for identical capabilities
- Consider usage patterns when selecting models
- Use cost-performance ratios for value optimization
Getting Started
- Visit the Dashboard at apipie.ai/dashboard
- APIpie Router login - Create an account for advanced features
- Explore model categories to understand available models
- Browse models using our filtering system
- Apply filters based on your requirements
- Compare models within groups for best options
- Review performance metrics with AI stats for your selected models
- Start testing with our router API integration
The APIpie Dashboard represents the most comprehensive AI API analytics platform available, serving as your top router for AI model selection. Our streaming router provides the insights you need to make informed decisions about AI and ML model selection. Whether you're comparing OpenAI competitors, seeking open source AI API alternatives, or need a reliable top ranked router platform, our dashboard provides the data-driven insights essential for optimal AI implementation.
Experience the future of AI model selection and management with the APIpie Global AI Operations Dashboard - your top router for AI APIs.