Smart Dashboard Grouping: Compare LMMs at a Glance


📢 New Smart Grouping on the Dashboard! 🔥
We've rolled out a new smart grouping feature on the Dashboard to make your experience even smoother and more efficient! 🚀
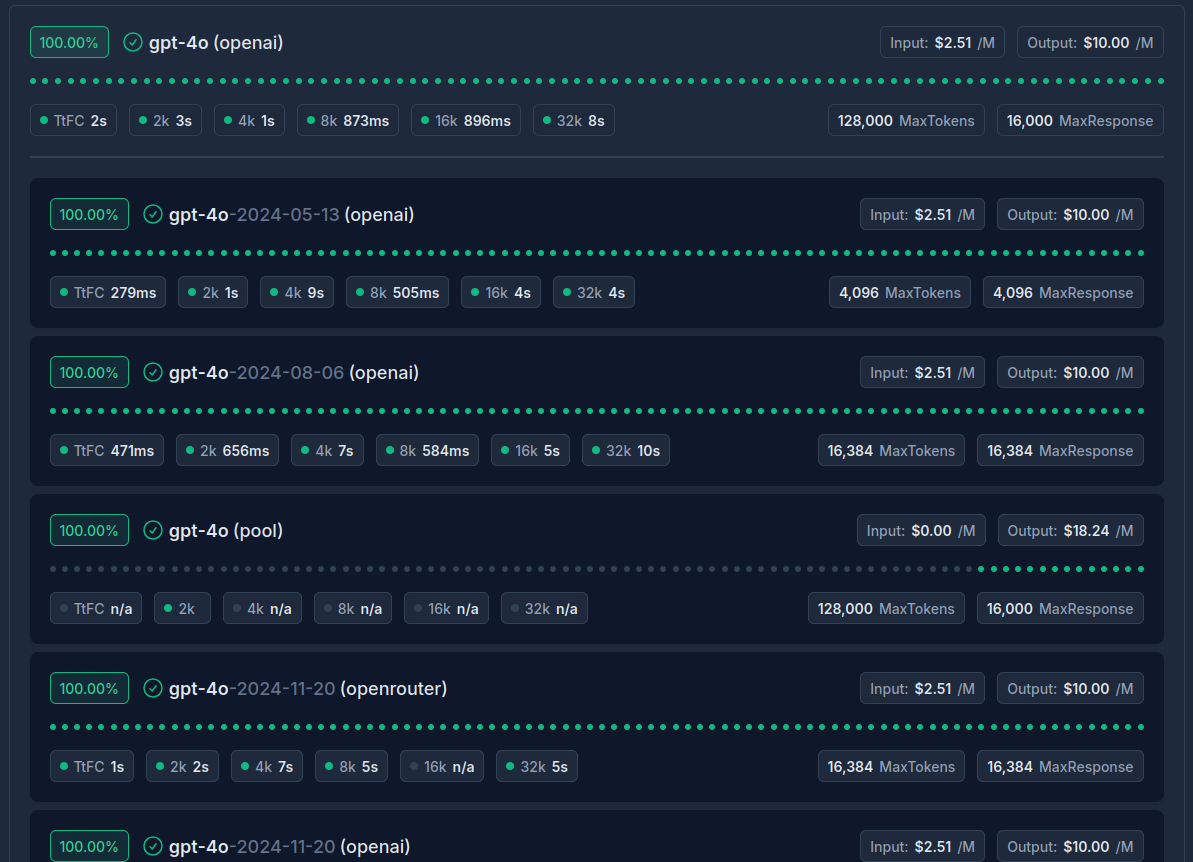
Now, all similar models are grouped together for quick and easy comparison. This means you can effortlessly see how pricing and latency vary across different providers and model variations at a glance. 👀
For example, as you see in the screenshot, all the GPT-4o models are neatly grouped, with model variation specific text differentiated from the base model name. We provide a great side by side comparison in a way you currently can't find elsewhere. We have availability stats, the actual real cost per million tokens captured using real cost analytics and have average latency by prompt/response size, and the "time to first chunk" to ensure the best experience for streaming chat.
Key Benefits
✅ Quickly compare performance and cost between providers and model variations
✅ See real-world cost analytics rather than advertised prices
✅ Compare latency metrics including "time to first chunk" for streaming
✅ Check availability stats to ensure reliable access
✅ Make informed decisions based on comprehensive metrics
We also have some more exciting features coming soon, a waterfall of new and innovative stuff coming soon.
Stay tuned for updates!
The APIpie Team 🥧